1. 목표 및 목적
- 최종목표: 동영상 파일을 통해 행동을 감지하는 시스템 구현.
- 투입물: 직접 촬영한 동영상 파일
- 산출물: 동영상 파일에 대한 class 도출

코드를 작성해 해당 영상이 무엇을 하는 동작인지 판단하는 알고리즘을 개발하는 것에 목적이 있다.
2. 예제
해당 목표를 위해 다음의 동영상을 참고했다.
https://youtu.be/_Q_7LyAkulA?si=4fqWmujydTFiNBpG
3. 개념설명
행동 모델은 keras의 'Video Classificaion with a CNN-RNN Architecture' 라이브러리를 사용해 구현한다.
3.1 CNN은 무엇인가
CNN이란 Convolutional Neural Network의 약어로 이미지와 같은 구조화된 격자 데이터를 처리하기 위해 설계된 딥 러닝 알고리즘을 의미한다. 이 알고리즘은 이미지 분류, 객체 감지, 이미지 분할, 얼굴인식 등에 사용된다.
해당 알고리즘은 다음과 같은 순서로 진행된다.
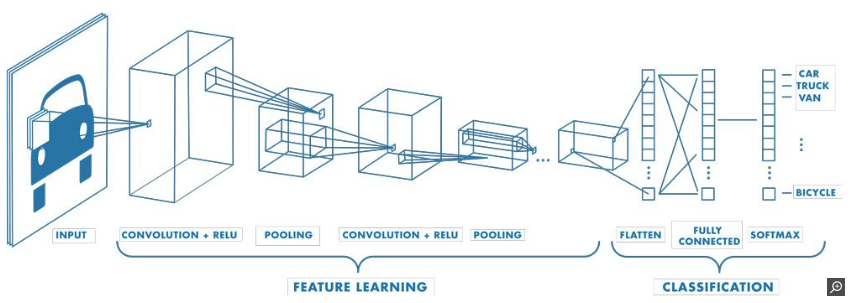
1. 특징 추출 - 패턴, 질감 등 이미지의 특징을 감지한다.
2. ReLU(Rectified Linear Unit) 계층 - 모델에 비선형성을 도입해 더 복잡한 기능을 학습할 수 있도록 구현한다.
3. 풀링 계층 - 입력 불륨의 크기를 줄여 계산 부하를 줄인다.
4. 완전 연결 계층 - 레이어를 연결해 상위 수준 추론을 수행한다.
5. 출력 계층 - 각 클래스에 대한 확률을 제공한다.
3.2 RNN은 무엇인가
RNN이란 Recurrent Neural Network의 약어로 순차 데이터를 처리하도록 설계된 신경망 유형이다. 기존 신경망과 달리 이전 입력에 대한 메모리를 유지하는 특징이 있다.
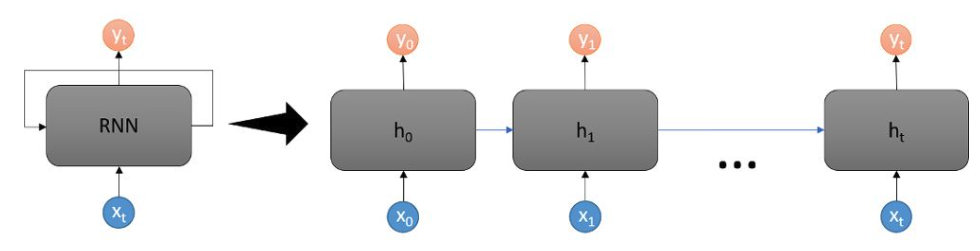
메모리 유지 특성이 있어 자연어 처리, 음성인식, 시계열 예측, 비디오 분석 등에 사용된다.
해당 알고리즘의 활용은 다음과 같다.
1. 순차 데이터 처리 - 시계열 데이터, 자연어 처리, 음성 인식 등에 관한 작업에 적합하다.
2. 반복 연결 - 기존 신경망은 입력과 출력이 주기를 갖지 않으나, RNN은 자체 연결되어 정보가 지속된다.
3. 은닉 상태 - 이전 입력에 대한 정보를 캡쳐하는 메모리 역할을 수행.
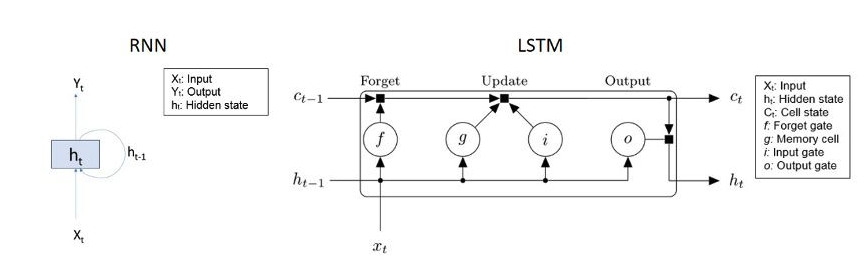
RNN의 변형
1. LSTM(장단기 기억)
LSTM은 장기 종속성을 처리하도록 설계된 RNN의 유형이다. 입력, 출력등을 사용해 정보를 제어한다. 결과적으로 정보를 보존하는데 사용되는 알고리즘 유형이다.
3.3 CNN-RNN의 결합이 어떤 의미를 갖는가
CNN-RNN을 결합하면 비디오 분류, 이미지 캡션 작성, 시계열 분석 등 공간 정보가 포함된 순차 데이터 작업에 이점을 제공한다. 결과적으로 CNN은 이미지 특징 추출의 영역을 맡고, RNN은 시간 순서에 따른 데이터를 처리한다고 이해하면 된다.
1. 공간특징 추출 - CNN은 이미지에서 특징을 추출. RNN은 이미지 데이터를 처리하지 않고, 시간 순서로 배열 가능
2. 시간 순서 학습 - 시간순서가 중요한 작업에 적합.
3. 대량 입력 데이터 처리 - CNN이 입력 데이터의 차원을 줄여, RNN만 사용하는 것보다 크기가 큰 이미지 및 비디오 처리가 가능하다
4. 일반화 - 지속시간에 따른 내용의 변화가 발생하는 데이터에 적합하다.
4. 직접 진행해보자


Colab이란 구글에서 제공하는 클라우드 기반 주피터(Jupyter) 노트북 환경을 의미한다.
해당 Colab파일은 구글 드라이브에 저장 가능하며, GPU를 빌려 쓸 수 있다는 막강한 강점을 제공한다.
그래서 무조건 런타임 유형변경 - T4 GPU 사용을 클릭해야한다.
Dataset Preporcessing 탭에서 train학습이 이뤄진다. 해당 학습에 많은 시간이 소요되기에 GPU를 사용해 사용 시간을 줄일 수 있다. 데이터의 크기가 클수록 무조건 사용하는 것이 유리하다.

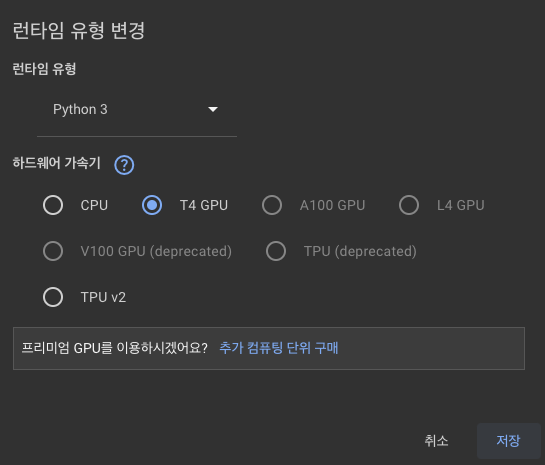
해당 런타임 유형변경까지 완료 되었으면 저장을 위해 구글 드라이브와 연동을 하는 것이 좋다.
해당 버튼을 누르면 다음 코드를 실행할 수 있도록 코드를 작성해준다.
좌측 재생 버튼을 눌러 실행한다.



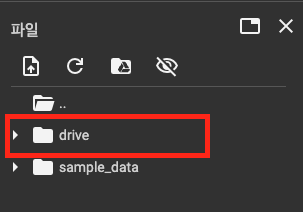
연결이 완료되면 drive칸이 뜬다. drive 파일에 저장하면 구글 드라이브에 동시에 연동되어 파일이 사라지지 않는다. 해당 작업이 완료되었으면 코드를 그대로 실행하면된다. 그러면 다음과 같은 사진이 뜬다.
5. 우리가 학습한 파일을 넣자
안타깝게도 간과한 사실이 있다. '직접 학습할 데이터를 넣는 것' 이를 위해서는 데이터셋의 변화가 필요하다.
기존 코드에서는 UCF101데이터 셋을 사용하였다. 많은 양의 데이터를 갖고 있어 더욱 추가하고 싶은 행동이 없다면 기존 데이터셋만을 이용해도 된다.

필자는 해당 데이터셋이 아닌 직접 학습할 데이터를 넣고 클래스에 대한 변경을 주고 싶었다. 이를 위해 다음과 같은 과정을 거쳤다.
1. UCF101 데이터 분석 - 그 결과 데이터셋은 5초 간격의 동영상으로 저장되어있었으며 동영상 제목에 행동분류 클래스가 적혀있었다.
2. 데이터 전처리 - UCF101데이터와 같이 5초간격으로 동영상을 잘라주고, 클래스를 입력했다.
3. 데이터 학습 - 클래스에 맞는 폴더에 동영상을 분류하고, 기존 클래스를 수정했다.
1. 데이터 전처리 과정
1.1 동영상 5초 분할
|
import os
import subprocess
def split_mov_file(input_file, output_directory, segment_time=5):
"""
Split a .mov file into smaller segments and save to a specified directory.
Parameters:
- input_file: str, path to the input .mov file.
- output_directory: str, path to the directory where the segments will be saved.
- segment_time: int, segment duration in seconds (default is 5 seconds).
"""
# Ensure the output directory exists
if not os.path.exists(output_directory):
os.makedirs(output_directory)
# Construct the output file pattern
output_pattern = os.path.join(output_directory, "저장할 파일 이름%03d.mov")
# Construct the ffmpeg command
command = [
"ffmpeg",
"-i", input_file, # Input file
"-c", "copy", # Copy codec (no re-encoding)
"-map", "0", # Map all streams
"-segment_time", str(segment_time), # Duration of each segment
"-f", "segment", # Format for splitting
"-reset_timestamps", "1", # Reset timestamps for each segment
output_pattern # Output pattern
]
# Execute the command
subprocess.run(command, check=True)
# Example usage
input_mov_file = "동영상 파일 경로 입력"
output_dir = "저장할 파일 경로 입력"
split_mov_file(input_mov_file, output_dir)
|
해당 코드를 실행하면 동영상을 5초로 분할해 저장한다. 해당 파일은 "파일명000", "파일명001"과 같이 저장된다. 상단의 segment_time에 해당하는 숫자를 조정하면 분할 시간을 조정할 수 있다.
1.2 dataset 폴더 안에 총 12가지 class 폴더를 만들어 각각 5초 영상을 넣어주었다.
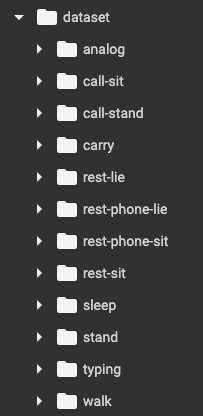
2. 데이터 학습 과정
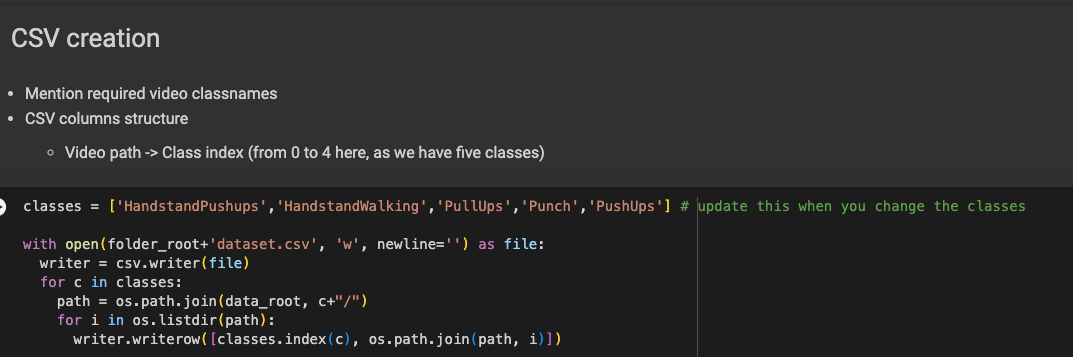
해당 코드에 친절하게 #update this when you change the classes 라고 적혀있다. 내가 원하는 클래스를 입력하면 된다.
필자의 경우 'analog','call-sit',''call-stand','carry','rest-lie','rest-phone-lie','rest-phone-sit','rest-sit','sleep','stand','typing','walk'로 총 12가지 행동을 기입했다.
나머지 부분은 코드를 그대로 실행하면된다.
6. 결과 확인
1. 테스트 정확도: 88.67%

2. 결과 출력
- 실제로 타이핑 하는 환경에서 99.89%나 정확하게 감지했다.
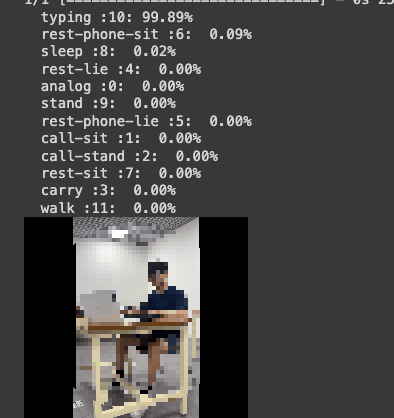
결론: 직접 데이터 셋을 바꿔서 결과를 출력해보는 과정을 겪었다. 생각보다 학습결과가 만족스러웠고, 데이터 셋이 더 다양해질수록 다양한 환경에서 활용도가 높아질 것이라 판단된다. 행동감지 시스템에 관심있는 분들은 한 번쯤 시도해보면 좋을 듯하다.
'AI' 카테고리의 다른 글
| [colab, visual studio code]PATH, 경로복사 방법 (0) | 2024.06.11 |
|---|---|
| AI 그림 무료 사이트, 유료 사이트 정리 (0) | 2023.11.19 |
| [딥러닝] YOLOV5를 이용한 객체 인식하기 1편(feat. 구글 코랩) (0) | 2023.07.30 |